

AIGC初体验——Stable Diffusion制作超棒图像(三)ControlNet功能
上一期我们简单讲了一下图生图功能,想必很多读者是意犹未尽。SD还有一个强大的插件叫ControlNet (简称CN),利用它我们能更生成更有创意并且符合逻辑的图片,本期我们将讲解ControlNet插件的安装使用。
一、ControlNet介绍
官网对它介绍只有两段话,

翻译成中文就是:
“ ControlNet是一个增加了额外条件来的神经网络结构来控制扩散模型(SD),它是AI图像生成游戏的改变者。它为SD带来了前所未有的控制水平。
ControlNet的革命性之处在于它解决了空间一致性问题。以前根本没有有效的方法来告诉人工智能模型要保留输入图像的哪些部分,而ControlNet引入一种方法,使稳定扩散模型能够使用额外的输入条件,准确地告诉模型要做什么,从而改变了这一现状。”
ControlNet是一个单独的插件,结合Prompt生成图像。可以与SD的文生图、图生图等功能一起使用。
二、ControlNet的安装和使用
安装和使用CN也是非常简单的,我们先启动SD,在“扩展-从网址下载”中输入http://github.com/Mikubill/sd-webui-controlnet,再点击应用更改并重载前端即可。如果失败的话也可以手动下载插件,然后解压到extensions文件夹中。
然后我们需要下载预处理器和模型。这一步可能会花比较多的时间。官方http://huggingface.co/lllyasviel/ControlNet/tree/main/models给的压缩包很大,每个都有5个多G,但是其实这些模型有很大的重复部分,这对我们这些硬盘吃紧的人来说很不友好。
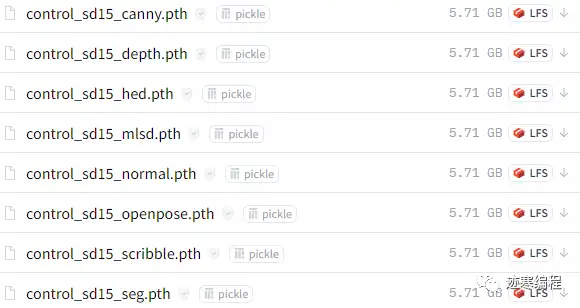
为此,迹寒专门进行了资源裁剪,只保留了模型的有效部分,所有模型加起来才9个G。你也可以挑想要的进行下载。
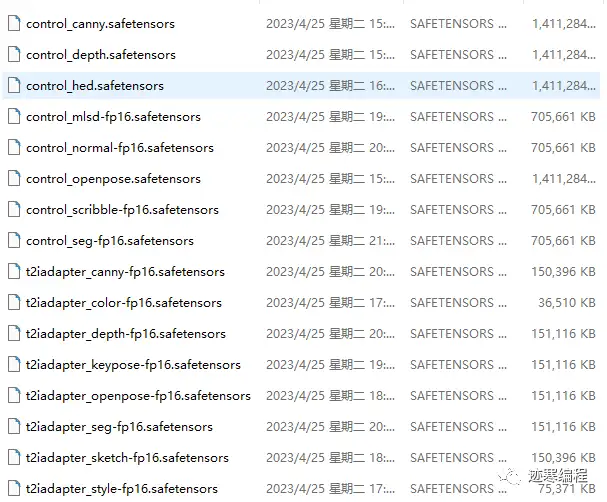
ControlNet 目前提供的预训模型,可用性完成度更高。而 T2I-Adapter ”在工程上设计和实现得更简洁和灵活,更容易集成和扩展”。
小技巧
CN模型获取方法很简单,只要动动手指头就行。关注【迹寒编程】回复【controlnet模型】获取下载方式(用的是夸克网盘,百度网盘限速太恶心了)。
下载完需要将模型放入models\ControlNet文件夹下,然后重启SD,点击刷新按钮 ️,应该可以看到“预处理器”和“模型”分别多了很多项:
预处理器:
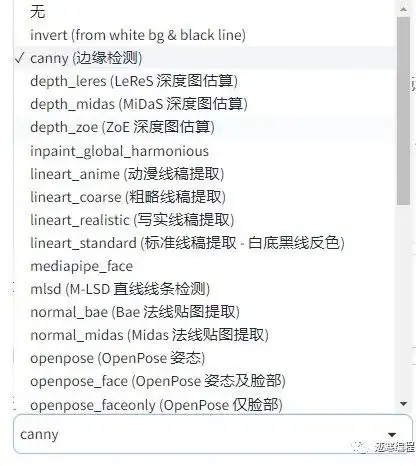
模型:

(1)界面介绍
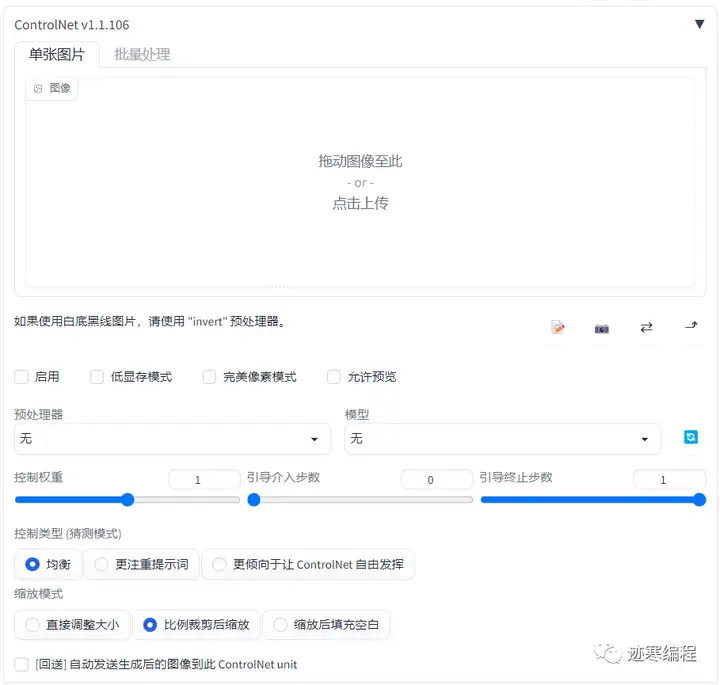
“工欲善其事,必先利其器”。我们简单了解一下界面。首先,我们看到最上面和图生图一样,有一个图像上传区域。然后右下方可以看到四个图标:
1) 表示新建画布,你可以在上面涂鸦,然后生成图像。(灵魂画手的福音)
2) 打开电脑摄像头(如果有的话),可以对自拍进行处理。
3)对电脑摄像头画面取镜像。
4)将图像尺寸发送到SD。这个功能很实用,以免忘记修改上方的图像大小。
正下面是四个选项框。
启用:选中此框以启用ControlNet,否则就不起作用。
低显存模式:顾名思义,如果你显存很低,就开启这个选项。
完美像素模式:可以生成更高质量的图像。
允许预览:将预处理器的结果显示出来。这个选项非常有用,建议勾选:
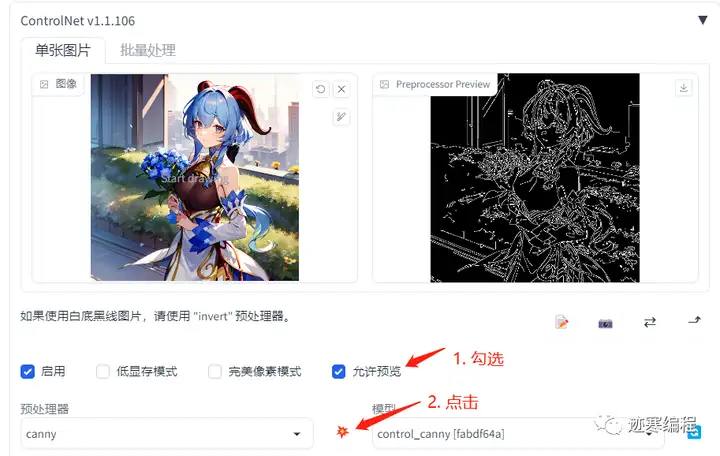
注意要点一下 按钮才能生效。
预处理器:对图像作预处理。这一步不需要很多资源,我们很快就能看到结果。
模型:ControlNet模型。预处理可以为空,但模型一定要有!
然后是一些参数相关的:
控制权重: ControlNet的权重,代表使用ControlNet生成图片的权重占比影响。
引导介入步数:从哪一步开始,ControlNet开始生效。这个值介于0-1。
引导终止步数:从哪一步开始,ControlNet结束生效。这个值介于0-1。
控制类型:有三个选项:“均衡”、“更注重提示词”和“更倾向于让ControlNet自由发挥”。这个理解起来不难,大家酌情使用。
缩放模式:有“直接调整大小”、“比例裁剪后缩放”和“缩放后填充空白”。根据需要进行选择。
[回送] 自动发送生成后的图像到此 ControlNet unit:将生成的结果做成ControlNet输入。用于多轮次迭代。
准备工作完成了,下面我们开始体验吧!
三、体验ControlNet
模型固定为Anything-V4.5。提示词依据情况设定,反提示词为EasyNegative, badhandv4。
StableDiffusion模型获取方式也可以在关注公众号并输入【StableDiffusion模型】获取。
(1)识别边缘
canny 用于识别输入图像的边缘信息。设置如下:
例如我们现在有一张手捧鲜花的甘雨图:

预处理识别边缘后的结果:

不加任何提示词,生成一个新图像,”啊,妹妹你是谁?“

是不是很神奇呢?canny的一个常见用途是提取线稿,在此基础上生成不同风格的图片。
(2)深度信息
depth用于获取图像的深度信息。大家听说过景深这个概念吧,深度信息和这个类似。人类为什么有两只眼睛?除了对称美以外,很重要的原因是为了形成立体视觉,获取深度信息。
另外还有一些参数,一般默认就好:
以下面还是以不上班的甘雨为例,采用LeRes深度图估算:

得到的深度图长这样,颜色越深表示距离观测者越远:

生成的图片是以此深度图为基础的,生成的画面就很有意思了,人物和背景的轮廓没有变,但内容大变样。

甘雨的角变成了辫子,可见CN的创意还是很棒的。
(3)线稿提取
前面我们介绍了canny边缘图,但其边界还是比较硬的,怎么样才能获得那种素描的效果呢?答案就是hed啦~
我们来看一个例子,还是王小美姐姐的例子:

预处理得到的线稿效果图,是不是有板绘那味了?

生成的图片中,我们可以看到一些光影和色调细节发生改变:

(4)建筑边缘提取
对于室内设计而言,线条大多数是直的,这就适合用mlsd进行边缘提取。

建筑边缘识别效果如下:

生成图的效果如下,这应该是...原始自然风格?不太懂。

这应该能为设计师提供不少灵感。
(5)姿态信息
姿态信息是最有趣而且最实用的信息之一,如果未来AI能生成动画的,那么根据姿态生成图像是必经之路。对应的CN模型为openpose。

对于这张图,姿态估计图中除了手部脚部细节,可以清晰看到人物躯体,并且是符合人物比例的。
做一下笔记
<br/>openpose
提取的骨骼图,面部细节缺失。<br/>openpose_face
支持识别面部,而身体的识别效果也比较好。
生成的图片也是同样的姿势。最有趣的是,我们可以用一个OpenposeEditor插件手动绘制我们想要实现的姿势。下载地址:http://github.com/fkunn1326/openpose-editor。
在选项图上可以看到Openpose编辑器选项。

首先点击“添加一张背景图片”,然后“Detect from image”,自动检测姿势。

我们移动关节点来修改姿势,然后发送到“文生图”可以生成一组相同姿势的人物图:
1)拿着小鼓的JK女孩,躺在床上

2)带着花帽蓄着胡须的男人

3)在图书馆整理图书的少女

4)依靠着空气的帅气男孩(bushi)

这功能必须好评!
(6)草图转图像
比如我们输入的是一张草图,能不能让AI上色呢?答案是Yes,利用scribble插件就可以拯救每一位有着绘画梦想的小可爱!
比如笔者简单画了一个奔跑的火柴人:

看看生成的图像:

连我自己都震惊了。灵魂画手的福音。(虽然脸部还欠缺一点)
此外你还可以上传自己画的线稿,比如迹寒之前画了一张:

看看生成的效果,Amazing!生成的图片风格与模型息息相关。如果要形成自己独一无二的风格,还需要自己训练模型才行。笔者有一个大胆的想法,以后的画家不仅会画画,而且会训练自己的模型 !
(7)图像分割
图像分割也是很实用的功能,对应的插件是seg。
例如下面是一张小女孩学习的图片,不同的色块表示不同的区域:

生成的图像,画面主要框架没变,但内容变了。

但是AI分割并不是万能的,在一些非常细节的地方,仍然会有瑕疵。
(8)不同的组合
其实这里面是有一些技巧在里面的:预处理器和模型需要一一对应吗?答案是NO。
我们来做一个实验,以canny, depth, openpose四个模型和三个预处理器为例制作一个图表。

可见有的组合会碰撞出创意的火花,有的组合是正正为负,不太河里的。通过合理的组合可以得到意想不到的效果。
(9)多通道
什么是多通道呢?简单来说,就是你希望CN在不同阶段调用不同的模型。生成的图片通常会有不同模型的特征。下面我们来演示一下:
首先启用多通道。在“设置-ControlNet”,把“多重 ControlNet 的最大模型数量”调到1以上就算开启了。回来打开CN选项卡,变成了这样:

然后我们来体验一下,将下面两张图片:
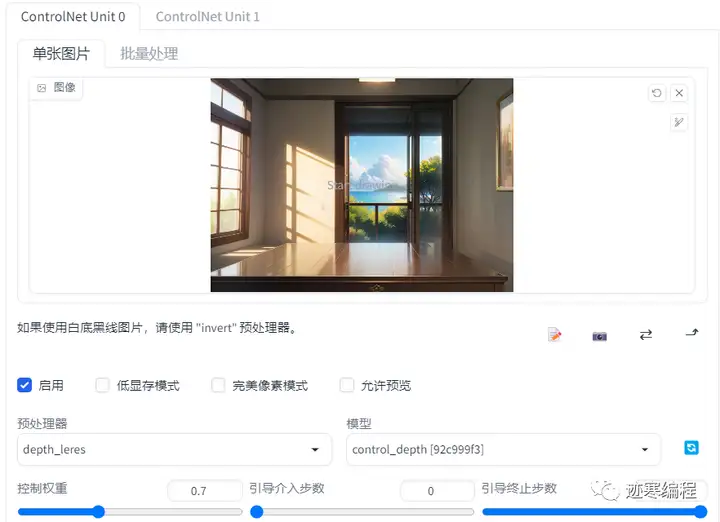

得到的图片长这样:

女孩出现在了我们设定的场景,并且画面具有上面两幅图像的特征。
如何生成更好的调整参数,达到风格各异的效果,还需要大家多多尝试~
三、总结
本期介绍了ControlNet的部分用法,算是抛砖引玉。包括识别边缘、深度信息、线稿提取、建筑边缘提取、姿态信息、草图转图像、图像分割、组合、多通道等等。内容比较多,需要自己亲自尝试。当然迹寒也会整理一份素材集,用于大家练习~
本期就到这里啦。下期我们将介绍《模型融合和训练》,请持续关注哟~
我是迹寒,下期再见!
参考资料:
[1] https://openai.wiki/stable-diffusion-img2img.html
[2] https://zhuanlan.zhihu.com/p/619120794
[3] https://openai.wiki/controlnet-v11-up.html
往期精彩